A Quick, Simple Example of Creating Dummy Variables Using Python Pandas
Problem
Many machine learning algorithms simply can’t be applied to columns that contain non-numeric values (such as categories that are indicated as strings like “Chicago”, “Boston”, or “New York”). For example. something like this:
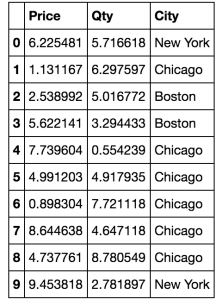
Sample Data
While there are a number of approaches for addressing this, and some approaches work better for some algorithms than for others, the Pandas library makes it easy to create “dummy variables” for each of the categorical values in a column. This means that each of the values in the columns will be represented as a separate column in the data frame.
In our example, a new column would be created for Chicago, Boston, and New York and a value of 0 or 1 would be set in that column accordingly. Like this:
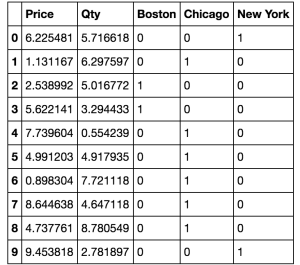
Sample Data with One-Hot Encoding
Solution
This code snippet shows how easy it is to do this (just lines 12, 15, and 18 if you already have your data loaded into a data-frame). The end result is the data-frame shown above:
#import pandas and numpy
import pandas as pd
import numpy as np
#create dataframe with some random data
df = pd.DataFrame(np.random.rand(10, 2) * 10, columns=['Price', 'Qty'])
#add a column with random string values that would need to have dummy variables created for them
df['City'] = [np.random.choice(('Chicago', 'Boston', 'New York')) for i in range(df.shape[0])]
#create dummy variables for the column
dummies = pd.get_dummies(df['City'])
#drop the original column
df = df.drop('City', axis=1)
#add dummy variables
df = df.join(dummies)
print(df)
Here are some of my other posts on Pandas.


